客舍青青The finger falls into a poem, characters fly through my fingers.2024-05-01T10:34:38.736Zhttps://www.caiyifan.cn/Ifan TsaiHexok8s first commit 源码分析之 Cloudcfghttps://www.caiyifan.cn/p/a35ad04f.html2022-10-01T09:51:30.000Z2024-05-01T10:34:38.736Z上一次分析了api server的源码,这一次来分析 cloudcfg 的源码。
简介
cloudcfg 可以看做是 kubectl 的前身,负责与 API server 的交互,只存在于上古时代的 k8s 中,我们现在接触到的都是叫做 kubectl 的命令行工具了。该组件做的事情非常简单,就是将用户的命令行操作转化为对 API server 的 HTTP 请求。
// The flag package provides a default help printer via -h switch var versionFlag *bool = flag.Bool("v", false, "Print the version number.") var httpServer *string = flag.String("h", "", "The host to connect to.") var config *string = flag.String("c", "", "Path to the config file.") var labelQuery *string = flag.String("l", "", "Label query to use for listing") var updatePeriod *time.Duration = flag.Duration("u", 60*time.Second, "Update interarrival in seconds") var portSpec *string = flag.String("p", "", "The port spec, comma-separated list of <external>:<internal>,...") var servicePort *int = flag.Int("s", -1, "If positive, create and run a corresponding service on this port, only used with 'run'") var authConfig *string = flag.String("auth", os.Getenv("HOME")+"/.kubernetes_auth", "Path to the auth info file. If missing, prompt the user")
最开始定义了 cloudcfg 命令行工具提供的所有参数。
main 函数中先从命令行中获取 method, api server 的 host,资源对象的类型以及鉴权参数。
// CreateTask takes the representation of a task. Returns the server's representation of the task, and an error, if it occurs func(client Client)CreateTask(task api.Task)(api.Task, error) { var result api.Task body, err := json.Marshal(task) if err == nil { _, err = client.rawRequest("POST", "tasks", bytes.NewBuffer(body), &result) } return result, err }
可以看到同样是通过请求 api server 来完成操作的。
回到命令行的 main 函数,创建 client 后调用cloudcfg.Update(flag.Arg(1), client, *updatePeriod)
// 代码路径:pkg/cloudcfg/cloudcfg.go // Perform a rolling update of a collection of tasks. // 'name' points to a replication controller. // 'client' is used for updating tasks. // 'updatePeriod' is the time between task updates. funcUpdate(name string, client client.ClientInterface, updatePeriod time.Duration)error { controller, err := client.GetReplicationController(name) if err != nil { return err } labels := controller.DesiredState.ReplicasInSet
taskList, err := client.ListTasks(labels) if err != nil { return err } for _, task := range taskList.Items { _, err = client.UpdateTask(task) if err != nil { return err } time.Sleep(updatePeriod) } returnnil }
大致逻辑是通过 name 获取 RC 对象,再通过 RC 对象的期望状态获取 tasks label,再通过 task label 来 list 所有 task 后更新 task。不过笔者没太看懂这里的更新逻辑,看上去把遍历 task 的时候由原封不动传回去了,或许第一个版本还不支持滚动更新?待笔者后续完整深入看完所有组件逻辑再来补充。
controller 操作
判断 method 为 run 时,拿到 image,replicas, name 后执行 RunController
var ( port = flag.Uint("port", 8080, "The port to listen on. Default 8080.") address = flag.String("address", "127.0.0.1", "The address on the local server to listen to. Default 127.0.0.1") apiPrefix = flag.String("api_prefix", "/api/v1beta1", "The prefix for API requests on the server. Default '/api/v1beta1'") etcdServerList, machineList util.StringList )
funcinit() { flag.Var(&etcdServerList, "etcd_servers", "Servers for the etcd (http://ip:port), comma separated") flag.Var(&machineList, "machines", "List of machines to schedule onto, comma separated.") }
最开始定义了 api-server 启动所需要的相关参数,上古版本的 k8s 使用了标准库自带的 flag 库,其中 util.StringList实现了flag.Value接口。
func(sl *StringList)Set(value string)error { for _, s := range strings.Split(value, ",") { iflen(s) == 0 { return fmt.Errorf("value should not be an empty string") } *sl = append(*sl, s) } returnnil }
// 代码路径:pkg/registry/interfaces.go // TaskRegistry is an interface implemented by things that know how to store Task objects type TaskRegistry interface { // ListTasks obtains a list of tasks that match query. // Query may be nil in which case all tasks are returned. ListTasks(query *map[string]string) ([]api.Task, error) // Get a specific task GetTask(taskId string) (*api.Task, error) // Create a task based on a specification, schedule it onto a specific machine. CreateTask(machine string, task api.Task) error // Update an existing task UpdateTask(task api.Task) error // Delete an existing task DeleteTask(taskId string) error }
// 代码路径:pkg/registry/interfaces.go // ControllerRegistry is an interface for things that know how to store Controllers type ControllerRegistry interface { ListControllers() ([]api.ReplicationController, error) GetController(controllerId string) (*api.ReplicationController, error) CreateController(controller api.ReplicationController) error UpdateController(controller api.ReplicationController) error DeleteController(controllerId string) error }
structdm9000_plat_data *pdata = pdev->dev.platform_data; structboard_info *db;/* Point a board information structure */ structnet_device *ndev;/* struct net_device 为网络设备的抽象 */ constunsignedchar *mac_src; int ret = 0; int iosize; int i; u32 id_val;
/* Init network device */ ndev = alloc_etherdev(sizeof(struct board_info)); /* 同时为 ndev 和 db 申请内存, db 内存位于 ndev 后面 */ if (!ndev) { dev_err(&pdev->dev, "could not allocate device.\n"); return -ENOMEM; }
/* try reading the node address from the attached EEPROM */ /* platdata 设置了 DM9000_PLATF_NO_EEPROM flag, 所以这个读取无效 */ for (i = 0; i < 6; i += 2) dm9000_read_eeprom(db, i / 2, ndev->dev_addr+i);
if (!is_valid_ether_addr(ndev->dev_addr) && pdata != NULL) { mac_src = "platform data"; //memcpy(ndev->dev_addr, pdata->dev_addr, 6); /* mac from bootloader */ memcpy(ndev->dev_addr, mac, 6); /* 这是真正的设置 mac 地址, 其他设置均无效 */ }
if (!is_valid_ether_addr(ndev->dev_addr)) { /* try reading from mac */
mac_src = "chip"; for (i = 0; i < 6; i++) ndev->dev_addr[i] = ior(db, i+DM9000_PAR); }
if (!is_valid_ether_addr(ndev->dev_addr)) dev_warn(db->dev, "%s: Invalid ethernet MAC address. Please " "set using ifconfig\n", ndev->name);
platform_set_drvdata(pdev, ndev); ret = register_netdev(ndev); // 注册网络设备
/* * Open the interface. * The interface is opened whenever "ifconfig" actives it. */ staticintdm9000_open(struct net_device *dev) { board_info_t *db = netdev_priv(dev); unsignedlong irqflags = db->irq_res->flags & IRQF_TRIGGER_MASK;
if (netif_msg_ifup(db)) dev_dbg(db->dev, "enabling %s\n", dev->name);
/* If there is no IRQ type specified, default to something that * may work, and tell the user that this is a problem */
if (irqflags == IRQF_TRIGGER_NONE) dev_warn(db->dev, "WARNING: no IRQ resource flags set.\n");
通常情况下,网络驱动以中断方式接收数据,但是当数据量大的时候会频繁产生中断,CPU 要频繁去处理中断导致效率低下而不如纯轮询模式。在 kernel 2.5 之后引入了新的处理方式,叫 NAPI,综合了中断方式和轮询方式。NAPI 这个名字取得不知所云,据说由于当时未找到合适的名字,就叫 NAPI (New API),目前已经公认为专有名词了。
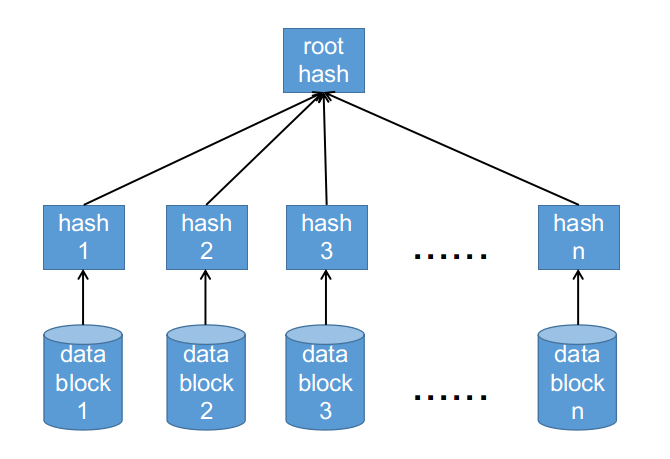
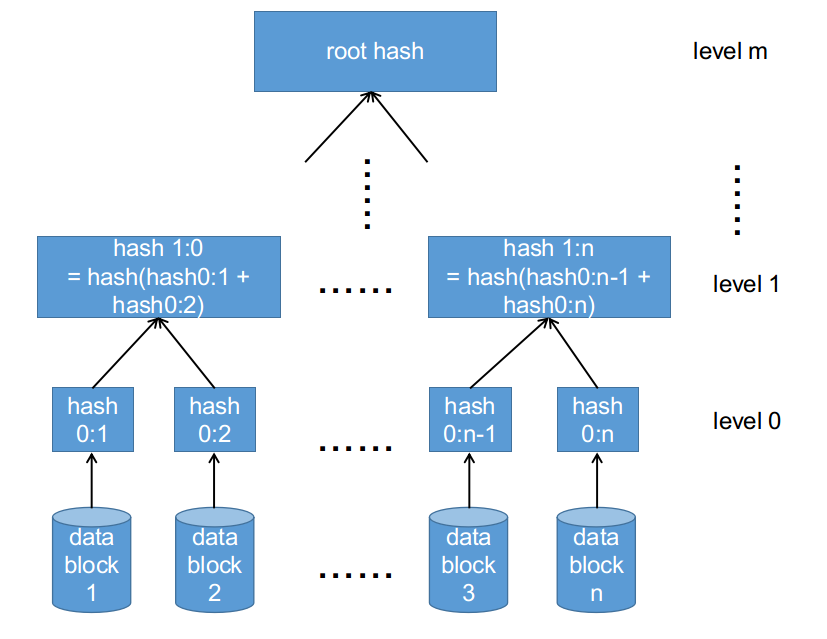
defcalc_hash_level_offsets(image_size, block_size, digest_size): """Calculate the offsets of all the hash-levels in a Merkle-tree. Arguments: image_size: The size of the image to calculate a Merkle-tree for. block_size: The block size, e.g. 4096. digest_size: The size of each hash, e.g. 32 for SHA-256. Returns: A tuple where the first argument is an array of offsets and the second is size of the tree, in bytes. """ level_offsets = [] # 用来存储每一层在bytearray中的偏移 level_sizes = [] # 每一层占用的大小 tree_size = 0# 树的大小
# 计算每一层在bytearray中的偏移 for n in range(0, num_levels): offset = 0 for m in range(n + 1, num_levels): offset += level_sizes[m] level_offsets.append(offset)
defgenerate_hash_tree(image, image_size, block_size, hash_alg_name, salt, digest_padding, hash_level_offsets, tree_size): """Generates a Merkle-tree for a file. Args: image: The image, as a file. image_size: The size of the image. block_size: The block size, e.g. 4096. hash_alg_name: The hash algorithm, e.g. 'sha256' or 'sha1'. salt: The salt to use. digest_padding: The padding for each digest. hash_level_offsets: The offsets from calc_hash_level_offsets(). tree_size: The size of the tree, in number of bytes. Returns: A tuple where the first element is the top-level hash and the second element is the hash-tree. """ hash_ret = bytearray(tree_size) hash_src_offset = 0 hash_src_size = image_size level_num = 0 while hash_src_size > block_size: level_output = '' remaining = hash_src_size while remaining > 0: hasher = hashlib.new(name=hash_alg_name, string=salt) # Only read from the file for the first level - for subsequent # levels, access the array we're building. # 第0层直接按照block_size读取image来进行hash if level_num == 0: image.seek(hash_src_offset + hash_src_size - remaining) data = image.read(min(remaining, block_size)) # 第0层之上的每一层都由取其下一层来进行hash,eg: 将第m-1层的数据分块hash后生成m层数据 else: offset = hash_level_offsets[level_num - 1] + hash_src_size - remaining # 以block_size为单位进行分块 data = hash_ret[offset:offset + block_size] hasher.update(data)
// require返回值即是cai.js中的module.exports对象 const cai = require('./cai') // 通过module.exports对象即可访问到cai模块中的add函数和str变量 let res = cai.add(1, 2) console.log(res) console.log(cai.str)
/* Claim our 256 reserved device numbers. Then register a class * that will key udev/mdev to add/remove /dev nodes. Last, register * the driver which manages those device numbers. */ BUILD_BUG_ON(N_SPI_MINORS > 256); /* 注册为字符设备驱动,为应用层提供调用接口 */ status = register_chrdev(SPIDEV_MAJOR, "spi", &spidev_fops); if (status < 0) return status;
fail_printk: printk("unable to get major %d for misc devices\n", MISC_MAJOR); class_destroy(misc_class); fail_remove: remove_proc_entry("misc", NULL); return err; }
// 动态分配次设备号 if (misc->minor == MISC_DYNAMIC_MINOR) { int i = find_first_zero_bit(misc_minors, DYNAMIC_MINORS); // 找到位图中第一个为0的bit if (i >= DYNAMIC_MINORS) { // 没有找到 mutex_unlock(&misc_mtx); return -EBUSY; } misc->minor = DYNAMIC_MINORS - i - 1; // 分配次设备号 set_bit(i, misc_minors); // 将分配的次设备号加入位图 }
// 生成设备号 dev = MKDEV(MISC_MAJOR, misc->minor);
// 注册设备 misc->this_device = device_create(misc_class, misc->parent, dev, misc, "%s", misc->name); if (IS_ERR(misc->this_device)) { int i = DYNAMIC_MINORS - misc->minor - 1; if (i < DYNAMIC_MINORS && i >= 0) clear_bit(i, misc_minors); err = PTR_ERR(misc->this_device); goto out; }
/* * Add it to the front, so that later devices can "override" * earlier defaults */ // 将已注册的驱动添加到链表上,open时可遍历链表来替换真正的fops list_add(&misc->list, &misc_list); out: mutex_unlock(&misc_mtx); return err; }
int __init i2c_register_board_info(int busnum, struct i2c_board_info const *info, unsigned len) { int status;
down_write(&__i2c_board_lock);
/* dynamic bus numbers will be assigned after the last static one */ // __i2c_first_dynamic_bus_num为全局未显式初始化变量,所以第一次进到这个函数,值为0 if (busnum >= __i2c_first_dynamic_bus_num) __i2c_first_dynamic_bus_num = busnum + 1;
for (status = 0; len; len--, info++) { structi2c_devinfo *devinfo;
devinfo = kzalloc(sizeof(*devinfo), GFP_KERNEL); if (!devinfo) { pr_debug("i2c-core: can't register boardinfo!\n"); status = -ENOMEM; break; }
staticinti2c_do_add_adapter(struct i2c_driver *driver, struct i2c_adapter *adap) { /* Detect supported devices on that bus, and instantiate them */ i2c_detect(adap, driver);
/* Let legacy drivers scan this bus for matching devices */ if (driver->attach_adapter) { /* We ignore the return code; if it fails, too bad */ driver->attach_adapter(adap); // 调用i2c-dev中的i2cdev_attach_adapter方法 } return0; }










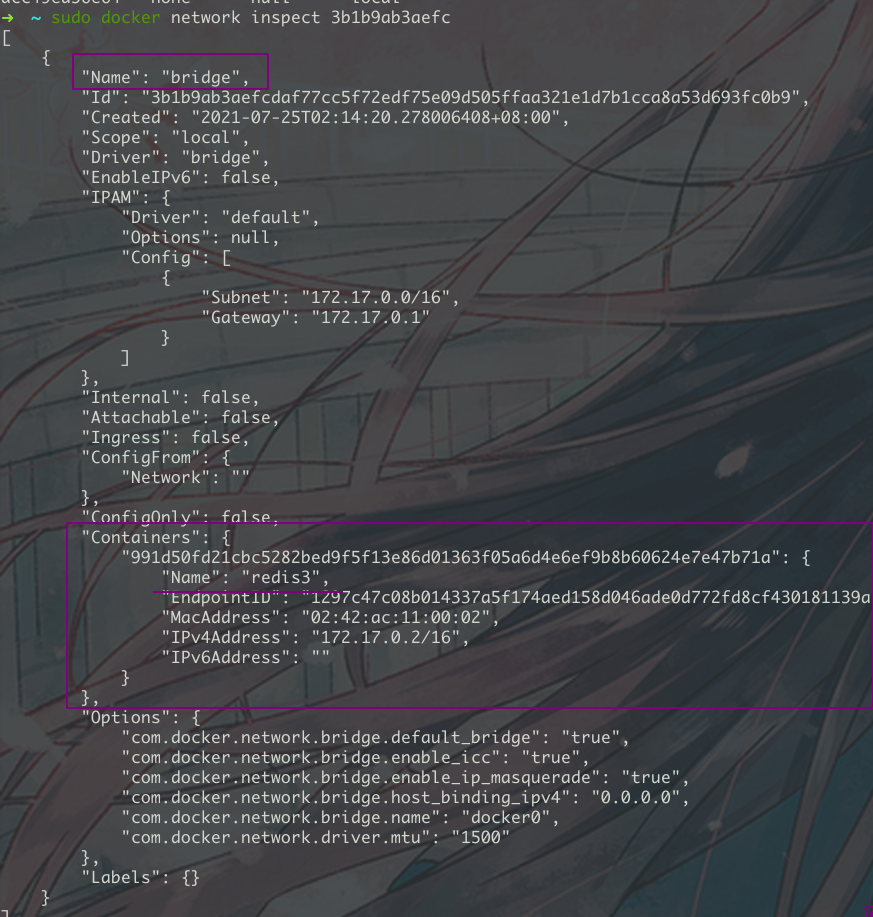

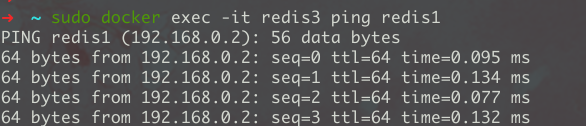
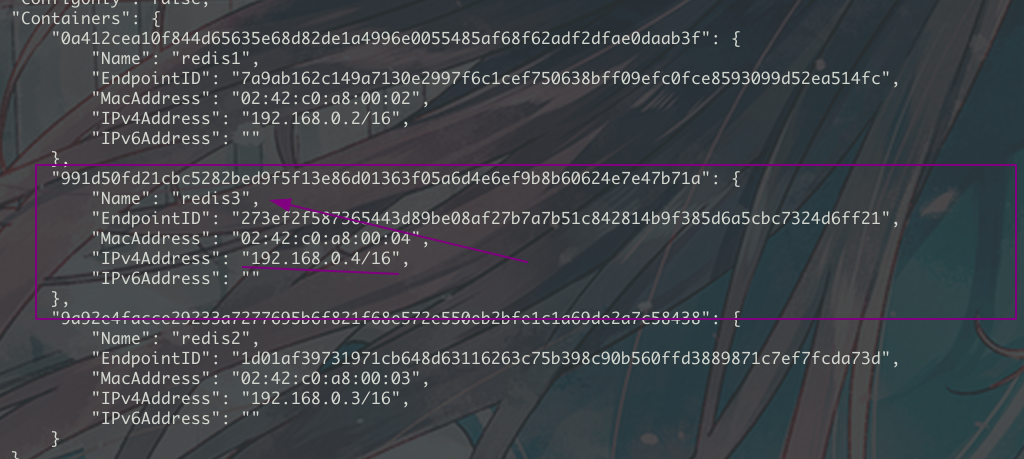
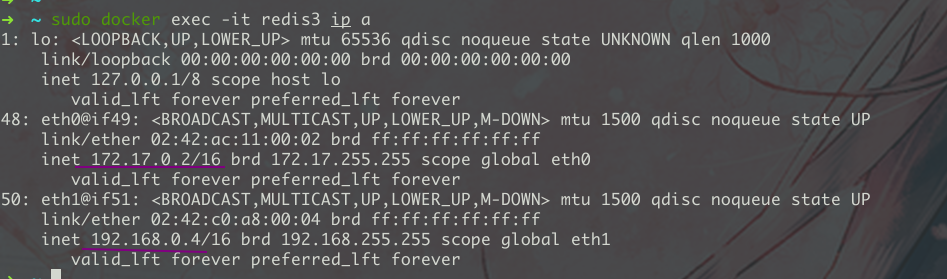 ]]>
]]>